Building support for securing a production environment


In our last post, we discussed the challenges of securing a production environment. Because production environments are linked to your company’s top line growth, the first step in being secure is understanding your company’s tolerance for different types of risks to your production environment. In this post, we show how to conduct a fast, lightweight risk assessment so that you can effectively communicate within your company about the value of securing the production environment.
How do I begin understanding my company’s risk tolerance?
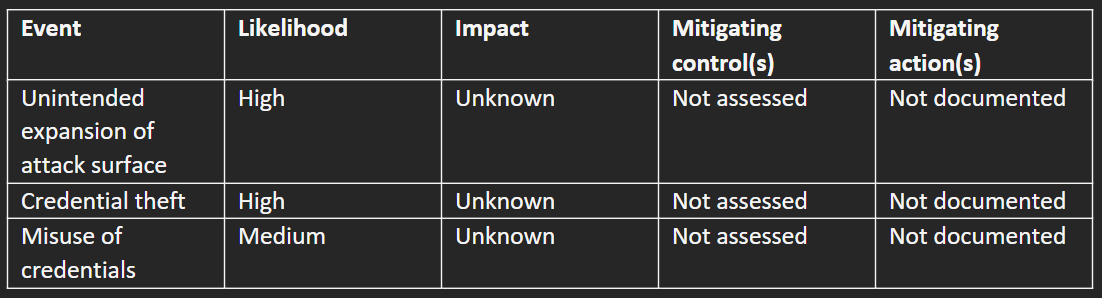
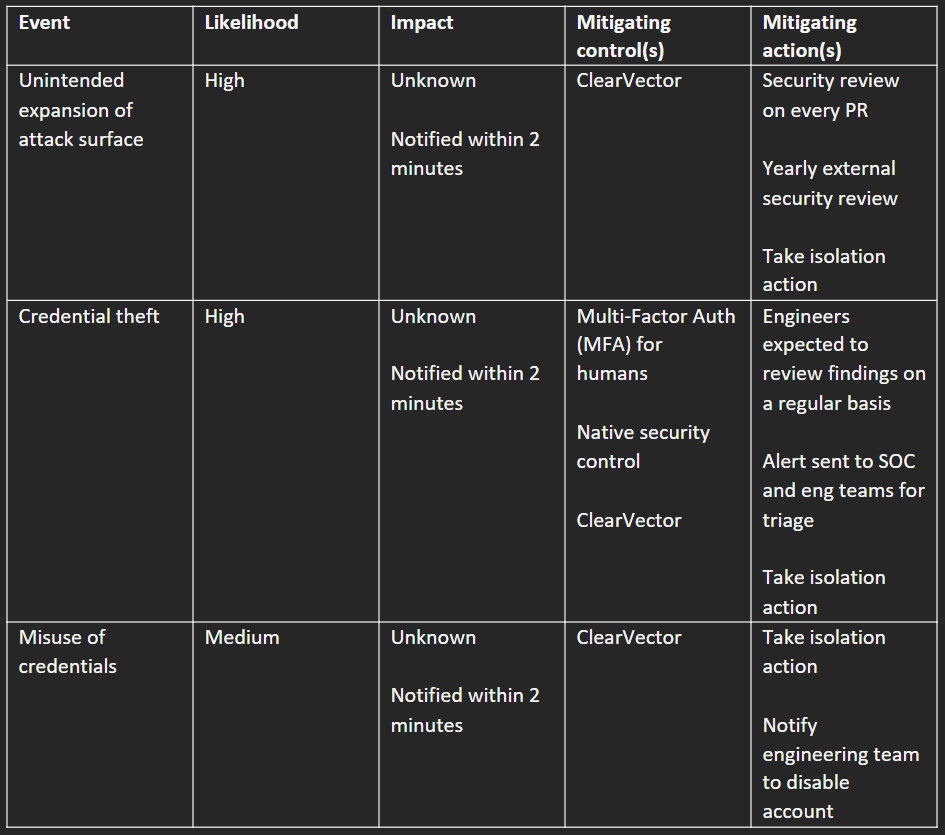
In just a few hours, you can begin to form an initial understanding of what risks are being implicitly or explicitly accepted at your company. In the spirit of the MVSP, start with the three events shown in Table A. If any of these three events happened in your production environment – unintended expansion of the attack surface, credential theft, or misuse of credentials – how would you handle that today? What would the impact be on your company? And how likely are these events to occur?
(Many comprehensive risk frameworks also attempt to quantify the impact – I don’t believe this is possible a priori. That said, in retrospect, the impact can be evaluated as part of a post-mortem analysis of an incident. Let me know if you’d like to chat about this further).
It may be tempting in these conversations to discuss technology stacks, analysts quadrants, or how "elite" the latest adversary post-exploitation TTP was – try to keep the focus on risk and people (identities).
What do I need to know about these events to secure my production environment?
Unintended attack surface expansion is a situation where a developer, engineer, or other user deploys a change that increases the risk to your production environment, without this being known in advance. Security is part of what product and engineering teams do, but they are also running quickly to ship software, and unintentional changes can increase risk to the organization. A couple simple examples are making a S3 bucket public or opening a security group to the world. We can expand this definition over time as we mature our security program to include traditional items such as supply chain management (vulnerability management), asset management, posture, etc.
Credential theft is where an adversary obtains credentials that provide access to the production environment. Loss of credentials or session hijacking are the well-known examples. But credential theft can also occur when an adversary exploits a known or non-public vulnerability in your production environment – and after successful exploitation of a vulnerability, the adversary has effectively stolen credentials because they are executing in the context of a valid session or as a particular “authorized” identity in your environment. Including this definition as part of credential theft helps to incorporate typical adversary TTPs as part of this risk assessment.
To date, as an industry we’ve talked at length about lateral movement in terms of Active Directory, but today we are seeing a significant uptick in credential theft followed by lateral movement from developer workstations into cloud environments, many times facilitated by a 3rd party IdP. This is a classic attacker method of living in the “cracks and gaps” to move between environments secured typically by different teams with different models of risk.
Misuse of credentials is when an authorized user shares credentials with an unauthorized person or uses their credentials in a way that is not consistent with policy. Historically this has been called multiple things, such as insider threat, UEBA, or been part of GRC as an audit function. With attacks against helpdesk and other similar employees on the rise, it’s extremely important to understand the “authorized” activity of identities in your environment.
While there are many other events that could be part of your comprehensive risk assessment, these three are the bare minimum to begin communicating the value of securing the production environment to your company’s leadership.
So how do I best communicate where we are and where we should go?
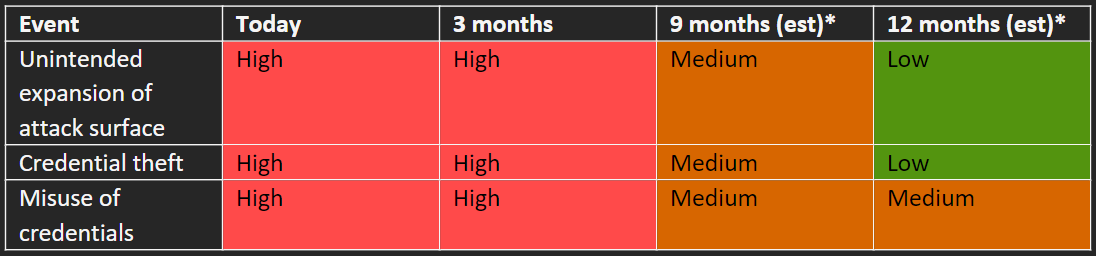
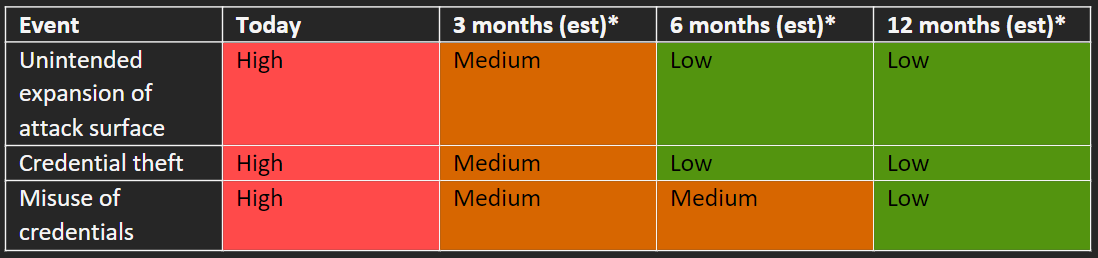
Table A is for you – the person responsible for securing the production environment. To communicate the current and future risk of the production environment with your executive team or board, imagine turning Table A into a heat map (Table B). Table B shows that at 3 months, you expect to have documented what’s currently in place, but that you still expect everything to be high risk. You caveat the 9- and 12-month columns as likely requiring additional investment to achieve and on a possibly longer timeframe. Along with Table B, you could include a timeline for initial analysis, and examples of public breaches to explain the types of impacts that might occur.
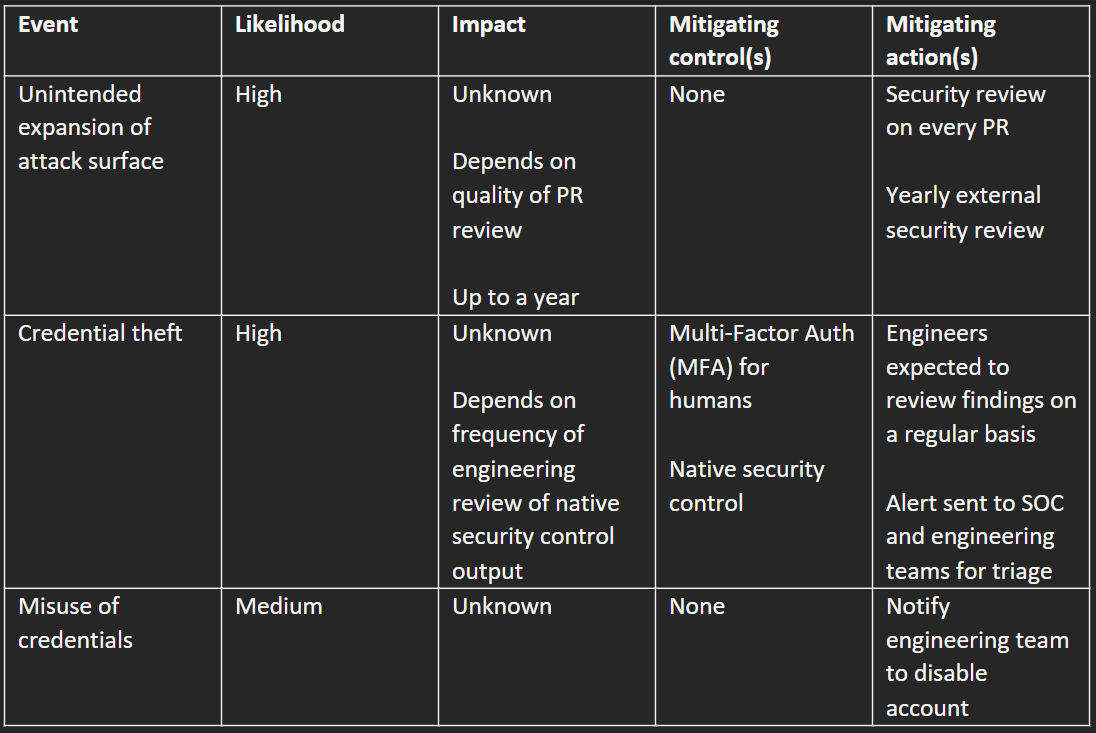
Next, after interviewing people across the company, you should be able to update Table A. Whereas the impacts of unintended expansion of attack surface and credential theft were completely unknown in Table A, in Table A.2, they are at least bounded by known controls and specific recurring actions.
Now, you go back to your executive team with an updated heat map (Table B.2):
You explain how you discovered there are some human processes in place, along with basic security controls for humans. However, you explain that shared secrets, machine identities, and 3rd and 4th party access still present a significant risk, and things are still generally high-risk overall. You explain you’ll be doing a further analysis of the options for investment to further reduce risk.
How do I build a business case to reduce risk to the production environment?
Table C is an exemplar you might use to evaluate potential solutions from build to buy.
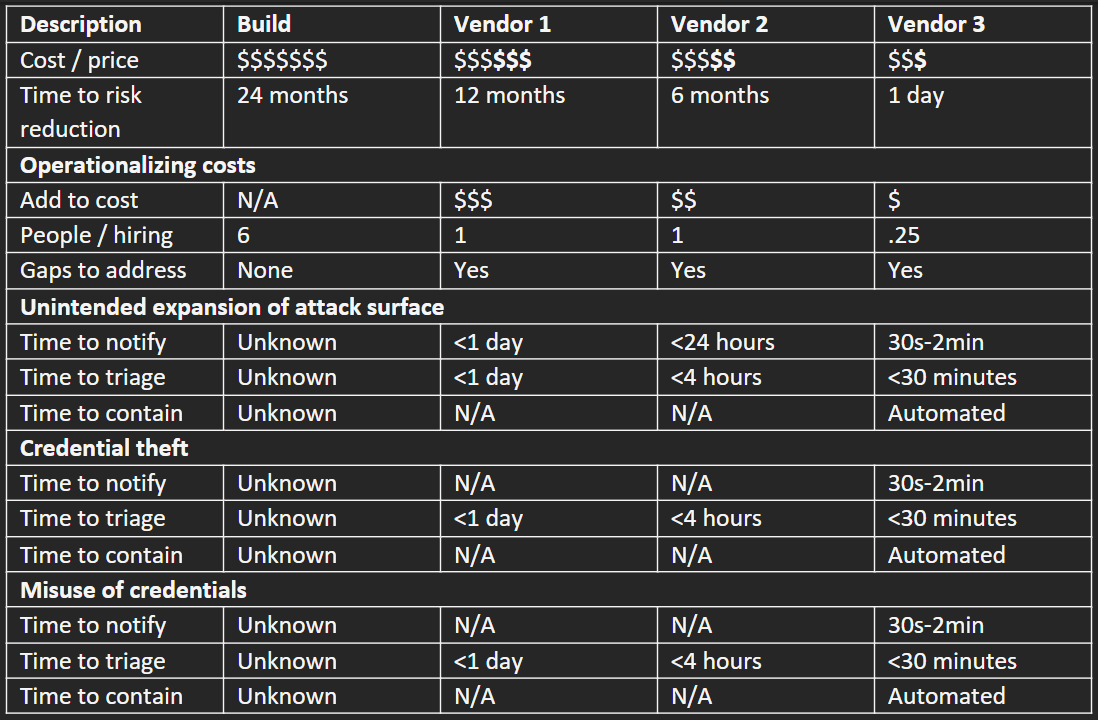
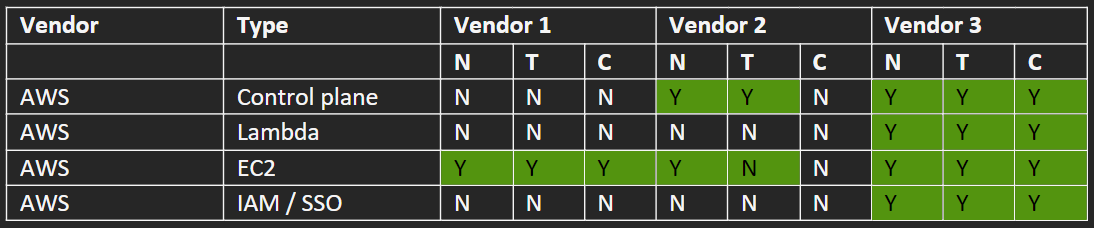
As supporting detail for Table C, you will need an additional matrix that tailors these use-cases for the technology and workloads in-use in your production environment. Table D shows the vendor and type of workload, followed by an evaluation matrix for “Notify”, “Triage”, and “Contain” capabilities for a typical non-cloud aware EDR/EPP product (Vendor 1), a typical SIEM/MDR solution (Vendor 2), and a purpose-built cloud-native solution (Vendor 3) such as ClearVector. Although this chart covers the high-level visibility and response capabilities, this does *not* cover the detection capabilities or differences. These differences are difficult to evaluate, and we’ll have future blogposts about this given our experience with many different testing approaches (in-house, MITRE, etc).
Next, as shown in Table A.3, you might say, here's how we can go from high risk to lower risk with investment:
Now, you go back to your executive team with your updated heat map shown in B.3 and the ask. You explain that today these events are still high risk, but you’ve evaluated the options and believe the company should invest $$ dollars to move from High to Low risk over the next 9-12 months.
And finally, you can sleep better at night knowing you have started to document and address the risk in your production environment!
Do you have your own way of framing securing production environments? We’d love to learn more and chat, contact us!